When working with Sitecore Search, encountering errors during crawling is common, especially when dealing with large JSON responses. Recently, I encountered a critical issue where the Sitecore Search web crawler failed due to exceeding the maximum payload size limit of 10MB..

Understanding the Error
The error message displayed was:
- Validation Error: The number of indexed documents should be bigger than 0.
- Javascript Error: Unexpected end of JSON input
- Cause: JSON parsing failed due to an incomplete response.
After some investigation, I identified the issue. The web crawler truncated the response when it exceeded 10MB. This action led to an incomplete JSON structure. As a result, it could not be parsed.
Solution: Handling Large JSON Payloads
To overcome this limitation, I followed below approach.
1> I first broke the response into smaller JSON files and uploaded them to Content Hub as assets.
2> Then, I created a single master JSON file that contained public links to all these chunked files.
3> The master JSON file had the following structure: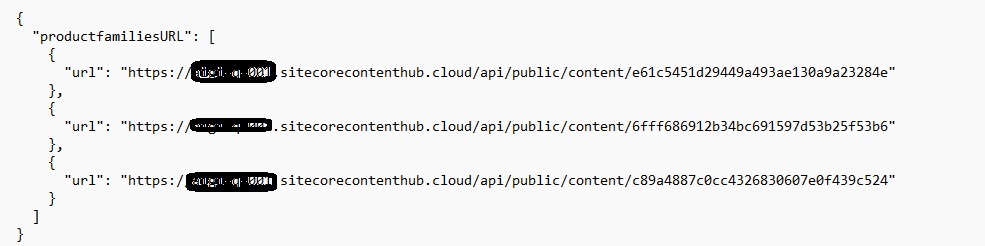
4> I uploaded this file to Content Hub and used its public link in the Triggers of the Web Crawler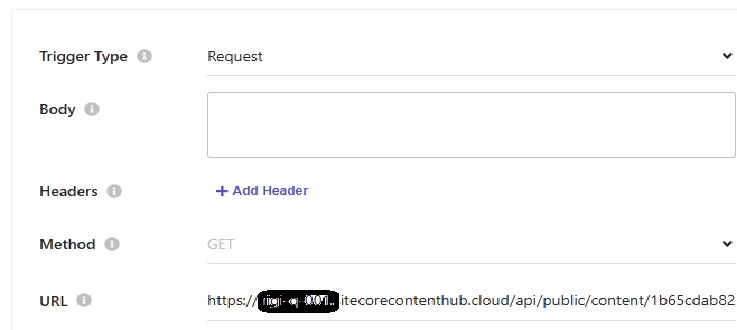
To complete the fix, I used Request Extractor and Document Extractor:
- Request Extractor:
- Enabled the crawler to fetch each JSON chunk individually from the master file.
- This allowed the crawler to retrieve data in manageable parts, preventing the payload from exceeding 10MB.
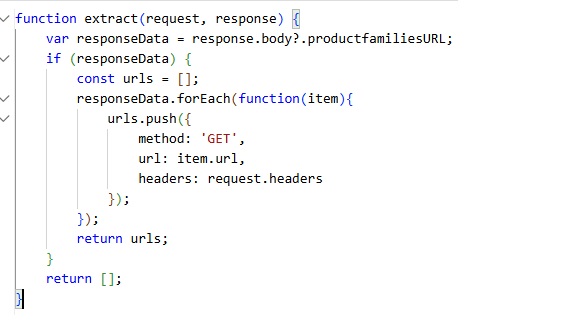
- Document Extractor:
- Once the data was split into chunks, I used this extractor to crawl and process the smaller parts individually.
- This ensured that all documents were indexed correctly without hitting the size limit.
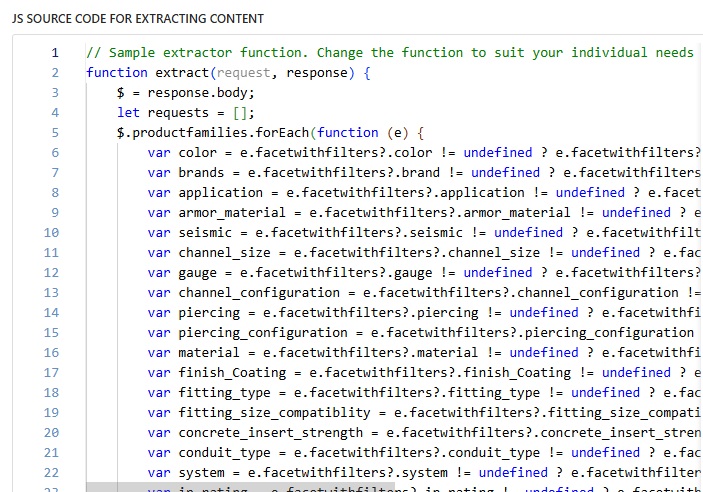
Key Takeaways
- Sitecore Search’s web crawler has a 10MB limit—ensure your responses do not exceed this.
- Use a Request Extractor to break large JSON documents into smaller chunks.
- Utilize a Document Extractor to process and index the chunks separately.
By implementing these strategies, I managed to successfully crawl and index large data sources without errors. If you’re facing similar issues, breaking down large responses is the way to go!
Let me know if you’ve faced this issue and how you tackled it.
